
My recent interests lie in scaling LLM/VLM agents for digital, visual, and 3D/4D automation, including: (i) coding and tool-use agents for real-world workflows and evaluation (Claw-Eval-Live, JarvisArt, JarvisEvo, JarvisX-Cowork), (ii) visual and creative agents for image generation, editing, restoration, and design artifacts (Unify-Agent, Gen-Searcher, JarvisIR, PosterCraft), and (iii) foundation models and benchmarks for 3D/4D world understanding and dynamic reasoning (IR3D-Bench, DynamicVerse, Thinking in Dynamics). These experiences span agent scaffold and harness design, task and evaluation construction, trajectory rollout and distillation, reinforcement learning/post-training, and multimodal reasoning. Current and previous focal areas include:
-
Multimodal LLM Agents
- Tool-using agents and creative workflows: JarvisArt, JarvisEvo, JarvisX-Cowork
- World-grounded synthesis agents: Unify-Agent, Gen-Searcher
-
Coding Benchmark
- Live agent coding benchmark: Claw-Eval-Live
-
3D/4D Large Foundation Models & Benchmarks
- 3D scene understanding and agentic inverse rendering: IR3D-Bench, HumanCrafter
- Dynamic 4D world modeling and reasoning: DynamicVerse, Diff4Splat, Thinking in Dynamics
-
AIGC / Unified Models
- Unified image generation and editing: Meta-CoT, iFSQ, ChatUMM
- Generative design and visual restoration: PosterCraft, JarvisIR, SnowMaster, AGLLDiff, DPLUT
✉️ Welcome to contact me for discussions and collaborations on VLM/LLM/Agent and reinforcement learning research.

JarvisX-Cowork: A Personal AI Creative Assistant for End-to-End Creative Workflows
An open-source creative assistant that supports end-to-end workflows from web reference search to image generation, refinement, video creation, and polished demos, decks, or docs.
Treating creative production as a unified agent workflow is more scalable than isolated tools. A single planner with shared memory and tool interfaces significantly reduces context switching and improves final output consistency.

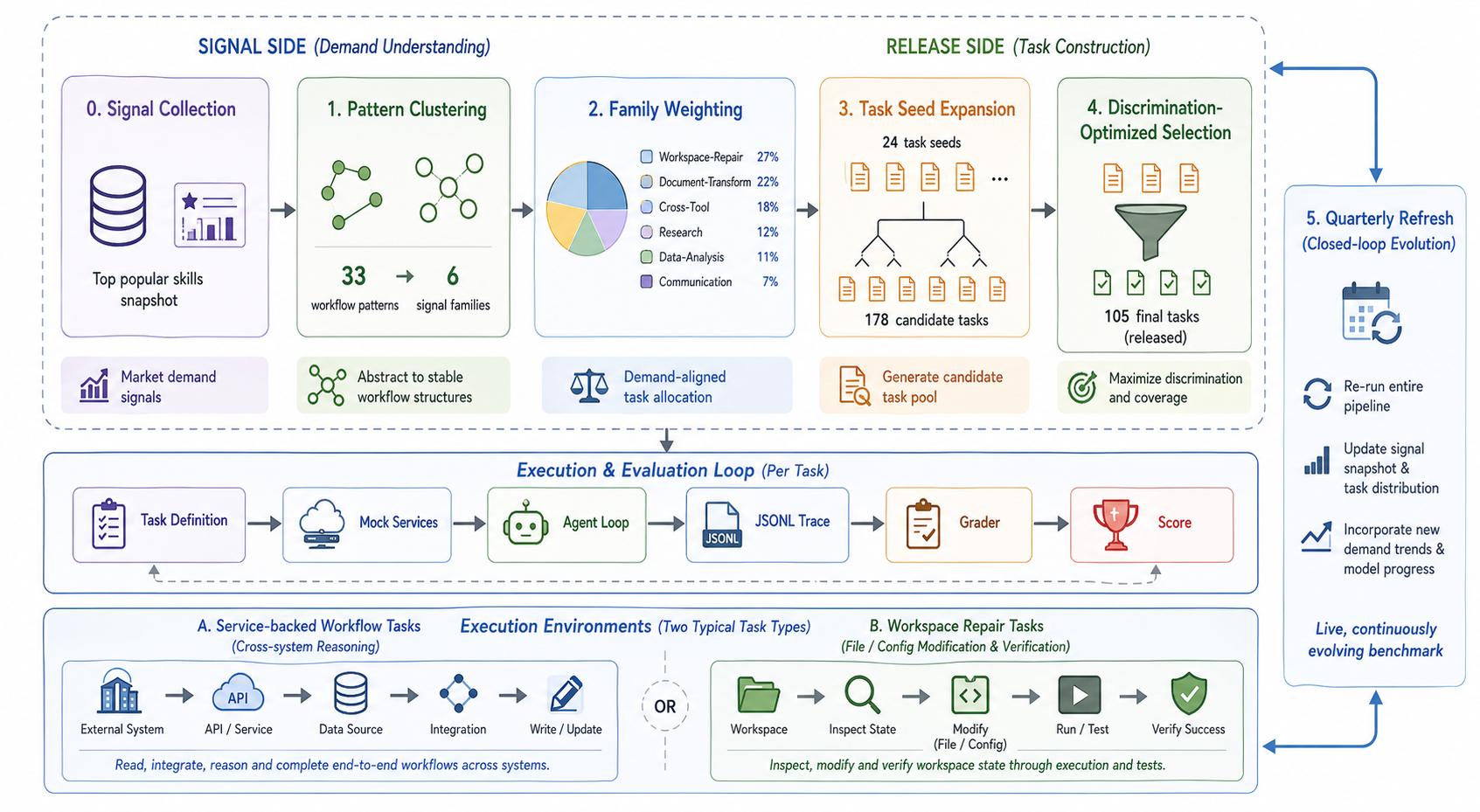
Claw-Eval-Live: A Live Agent Benchmark for Evolving Real-World Workflows
Chenxin Li, Zhengyang Tang, Mingxin Huang, Yunlong Lin, Shijue Huang, Shengyuan Liu, Bowen Ye, Rang Li, Lei Li, Benyou Wang, Yixuan Yuan
A live workflow-agent benchmark with refreshable demand signals and verifiable execution traces; 105 tasks across 22 categories, 13 frontier models, top model passes only 66.7%.
📄 PDF |
🌐 Project |
🤗 HF Paper |
💻 Code

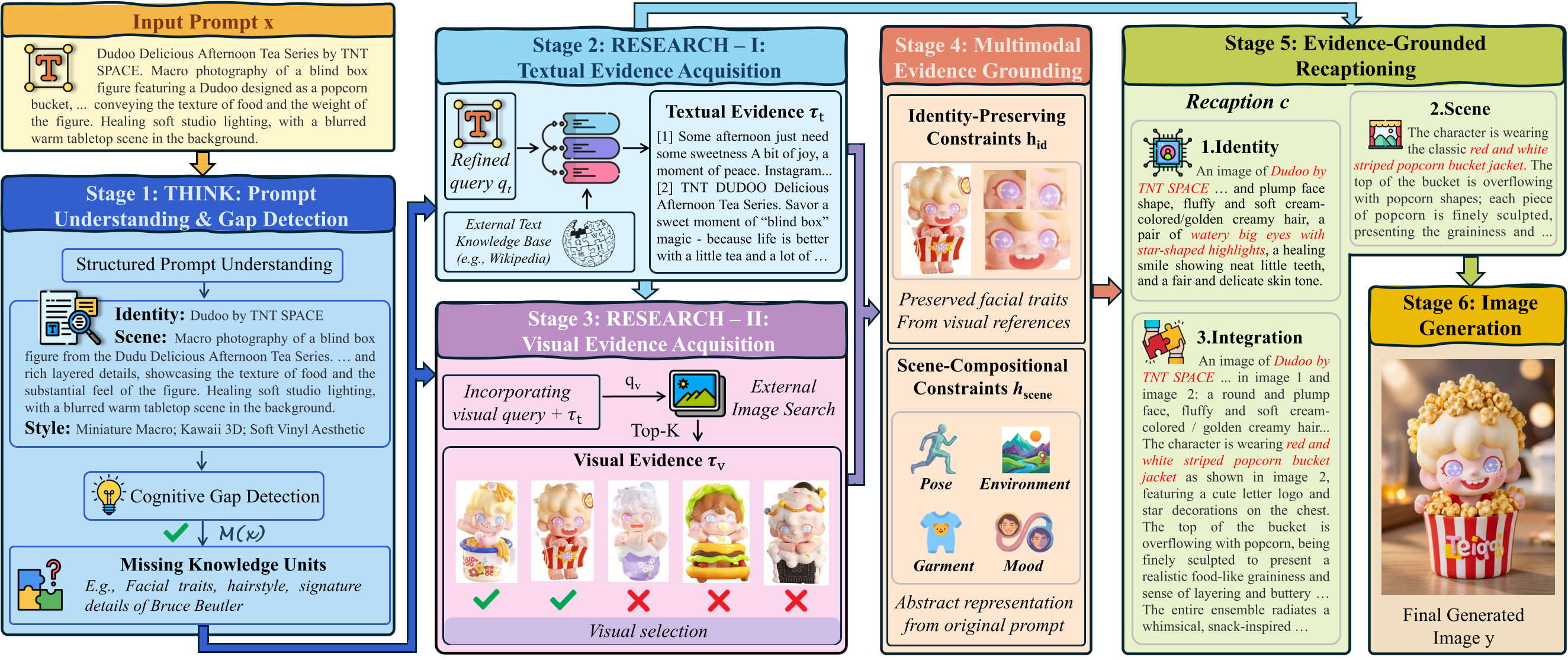
Unify-Agent: A Unified Multimodal Agent for World-Grounded Image Synthesis
Shuang Chen, Quanxin Shou, Hangting Chen, Yucheng Zhou, Kaituo Feng, Wenbo Hu, Yi-Fan Zhang, Yunlong Lin, Wenxuan Huang, Mingyang Song, Dasen Dai, Bolin Jiang, Manyuan Zhang, Shi-Xue Zhang, Zhengkai Jiang, Lucas Wang, Zhao Zhong, Yu Cheng, Nanyun Peng
Image synthesis quality improves when generation is grounded in an explicit world model rather than prompt-only decoding. Unifying perception, planning, and generation inside one agent reduces mismatch between intent and rendered scenes.

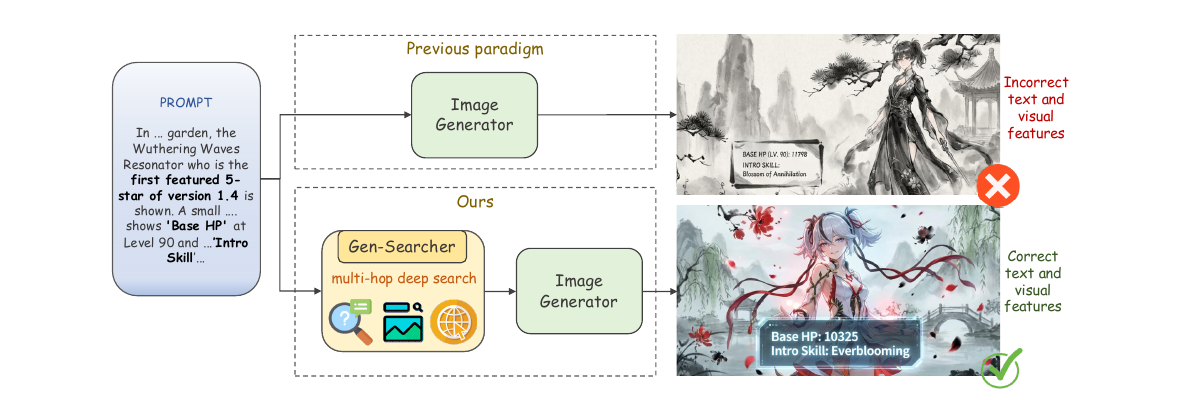
Gen-Searcher: Reinforcing Agentic Search for Image Generation
Kaituo Feng, Manyuan Zhang, Shuang Chen, Yunlong Lin, Kaixuan Fan, Yilei Jiang, Hongyu Li, Dian Zheng, Chenyang Wang, Xiangyu Yue
Better images come from better search trajectories before generation. Reinforcement learning over agentic search decisions gives stronger global composition and semantic faithfulness than one-shot prompt tuning.


Yunlong Lin*, Linqing Wang, Kunjie Lin, Zixu Lin*, Kaixiong Gong, Wenbo Li, Bin Lin, Zhenxi Li, Shiyi Zhang, Yuyang Peng, Wenxun Dai, Xinghao Ding3♣, Chunyu Wang†, Qinglin Lu†
A self-evolving loop between editor and evaluator provides stable long-horizon improvement for image editing agents. Reward shaping plus reflection-driven updates enables continual capability gains without handcrafting new pipelines for each task.
📄 PDF |
🌐 Project |
🤗 HF Paper |
💻 Code


JarvisArt: Liberating Human Artistic Creativity via an Intelligent Photo Retouching Agent
Yunlong Lin*, Zixu Lin*, Kunjie Lin*, Jinbin Bai, Panwang Pan, Chenxin Li, Haoyu Chen, Zhongdao Wang, Xinghao Ding†, Wenbo Li♣️, Shuicheng Yan†
High-quality artistic retouching is easier when the agent decomposes editing into interpretable subgoals and tool calls. This decomposition improves controllability for users while preserving strong aesthetic quality.
📄 PDF |
🌐 Project |
🤗 HF Paper |
🐦 Twitter |
📺 YouTube |
📹 Bilibili |
💻 Code

JarvisIR: Elevating Autonomous Driving Perception with Intelligent Image Restoration
Yunlong Lin*, Zixu Lin*, Haoyu Chen*, Panwang Pan*, Chenxin Li, Sixiang Chen, Kairun Wen, Yeying Jin, Wenbo Li, Xinghao Ding
Restoration should be optimized for downstream driving perception, not just pixel-level scores. Injecting agent-style decision signals into enhancement leads to more robust perception gains under adverse conditions.
📄 PDF |
🌐 Project |
🤗 Online Demo |
💻 Code

DynamicVerse: Physically-Aware Multimodal Modeling for Dynamic 4D Worlds
Kairun Wen, Yuzhi Huang, Runyu Chen, Hui Zheng, Yunlong Lin, Panwang Pan, Chenxin Li, Wenyan Cong, Jian Zhang, Junbin Lu, Chenguo Lin, Dilin Wang, Zhicheng Yan, Hongyu Xu, Justin Theiss, Yue Huang, Xinghao Ding, Rakesh Ranjan, Zhiwen Fan
Physical priors are critical for temporally consistent 4D world modeling. Combining physically-aware constraints with multimodal context improves both realism and controllability in dynamic scene generation.


PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework
Sixiang Chen, Jianyu Lai, Jialin Gao, Tian Ye, Haoyu Chen, Hengyu Shi, Shitong Shao, Yunlong Lin, Song Fei, Zhaohu Xing, Yeying Jin, Junfeng Luo, Xiaoming Wei, Lei Zhu
A unified framework can jointly handle layout planning and visual rendering instead of treating them as separate stages. This coupling yields better text-image harmony and more stable poster aesthetics.
📄 PDF |
🌐 Project |
💻 Code 
Yunlong Lin*, Tian Ye*, Sixiang Chen*, Zhenqi Fu, Yingying Wang, Wenhao Chai, Zhaohu Xing, Lei Zhu, Xinghao Ding.
Training-free enhancement can still be practical when diffusion models are guided by carefully designed global and local luminance priors. This design avoids expensive retraining while maintaining real-world robustness.

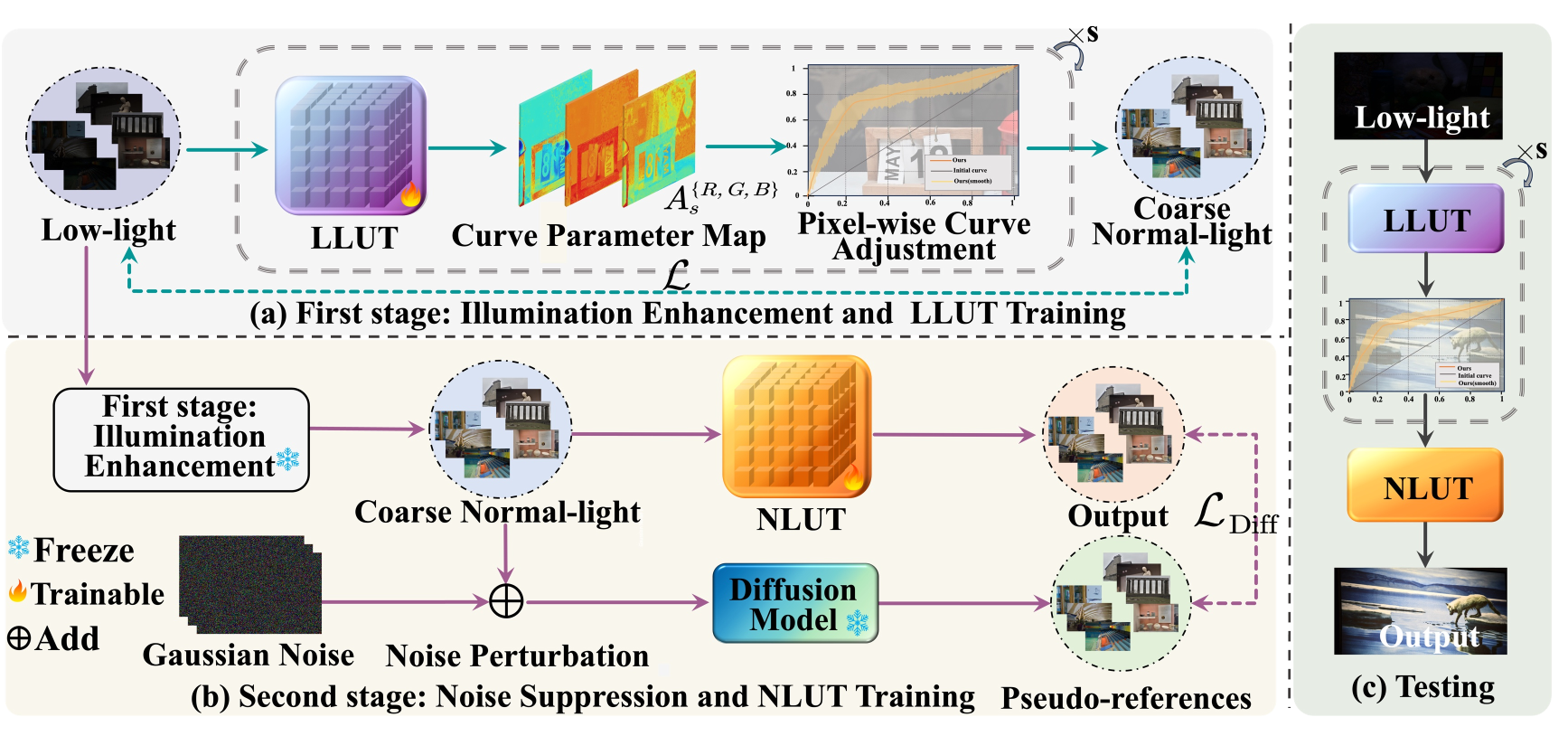
Unsupervised Low-light Image Enhancement with Lookup Tables and Diffusion Priors
Yunlong Lin*, Zhenqi Fu*, Kairun Wen, Tian Ye, Sixiang Chen, Ge Meng, Yingying Wang, Yue Huang, Xiaotong Tu, Xinghao Ding.
Lightweight LUT-based enhancement and diffusion priors are complementary rather than conflicting. Their combination provides a strong efficiency-quality trade-off for unsupervised low-light restoration.
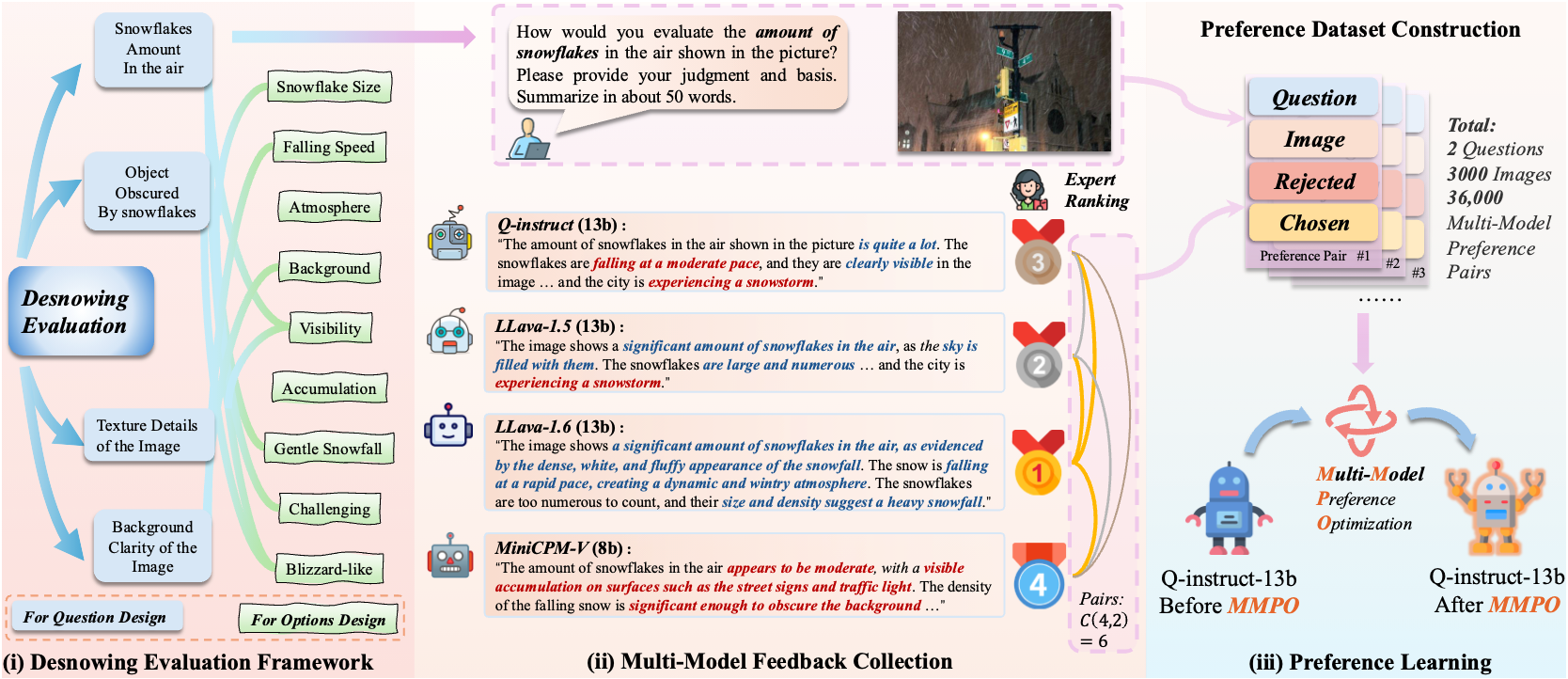
SnowMaster: Comprehensive Real-world Image Desnowing via MLLM with Multi-Model Feedback Optimization
Jianyu Lai*, Sixiang Chen*, Yunlong Lin, Tian Ye, Yun Liu, Song Fei, Zhaohu Xing, Hongtao Wu, Weiming Wang, Lei Zhu.
MLLM-driven feedback is effective for coordinating multiple restoration experts in difficult weather conditions. Multi-model feedback optimization improves desnowing quality and reduces brittle failure cases.
